Playwright
Playwright简介
Playwright是一个强大的Python库,仅用一个API即可自动执行Chromium、Firefox、WebKit等主流浏览器自动化操作,并同时支持以无头模式、有头模式运行。
无头模式(Headless Mode)
Headless模式是指在测试的执行过程中,不打开可视化的浏览器界面,
而是以后台潜默方式运行。
这意味着测试过程对用户是不可见的,所有操作都在后台自动进行。
Chromium 是 Google 的 Chrome 浏览器背后的引擎
Playwright提供的自动化技术是绿色的、功能强大、可靠且快速,支持Linux、Mac以及Windows操作系统。且支持移动端
由微软开源
最NB的地方就是不需要代码基础、也可以通过录制生成至少80%的代码来进行Web端的自动化测试
是一款真正意义上的Web端到端测试工具。
端到端测试(End-To-End Testing, 简称E2E测试)是一种从头到尾测试整个软件产品以确保应用程序流程按预期运行的技术。它定义了产品的系统依赖性,并确保所有集成部分按预期协同工作。
端到端测试的主要目的是通过模拟真实用户场景并验证被测系统及其组件的集成和数据完整性,主要从最终用户的体验进行测试。

特点
跨浏览器
Playwright 支持所有现代渲染引擎,包括Chromium、WebKit 和 Firefox
跨平台
在 Windows、Linux 和 MacOS 上进行本地或 CI、无头或有头测试
跨语言
在 TypeScript、JavaScript、Python、.NET、Java 中使用Playwright API
测试移动网络
适用于 Android 和 Mobile Safari 的 Google Chrome 原生移动仿真。相同的渲染引擎适用于您的桌面和云端。
学习成本低
通用Python语言,0代码基础也可录制脚本
Playwright环境配置
1.Playwright下载&安装
pip install playwright2.浏览器驱动下载&安装
(Chromeium、Firefox、Webkit等)
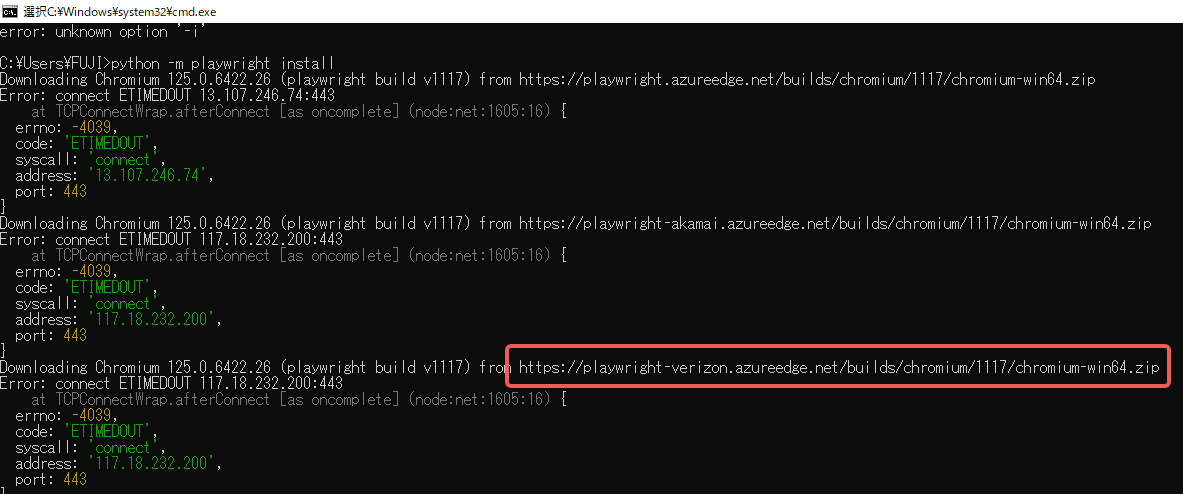
playwright install由于墙无法下载驱动时:
复制下载链接、手动下载压缩包并解压至对应路径即可
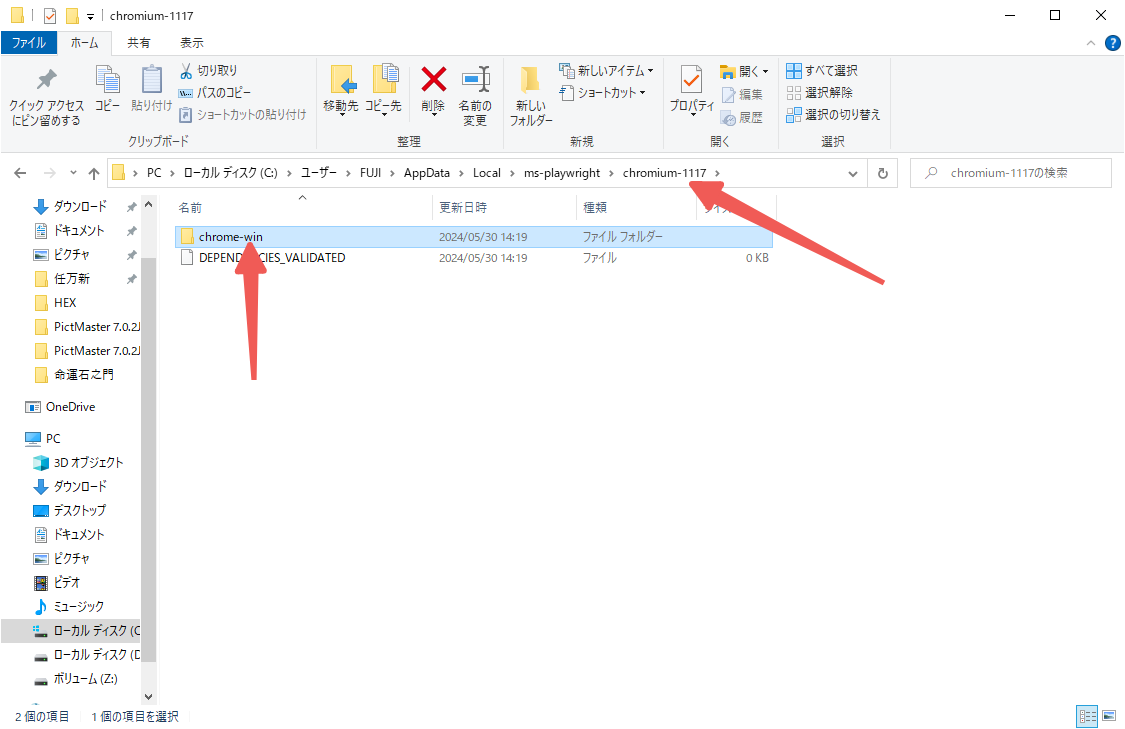
C:\Users\FUJI\AppData\Local\ms-playwright\chromium-xxxx
Playwright基础语法
脚本录制
playwright codegen [options] [url]例:
playwright codegen -o test_playwright.py --target python -b chromium --device="iPhone 12 Pro" https://www.baidu.com/playwright codegen -o test1.py --target python -b chromium#栗子
from playwright.sync_api import sync_playwright
def run(playwright):
browser = playwright.chromium.launch(headless=False)
page = browser.new_page()
page.goto('http://whatsmyuseragent.org/')
page.screenshot(path='example.png')
browser.close()
with sync_playwright() as playwright:
run(playwright)Browser相关
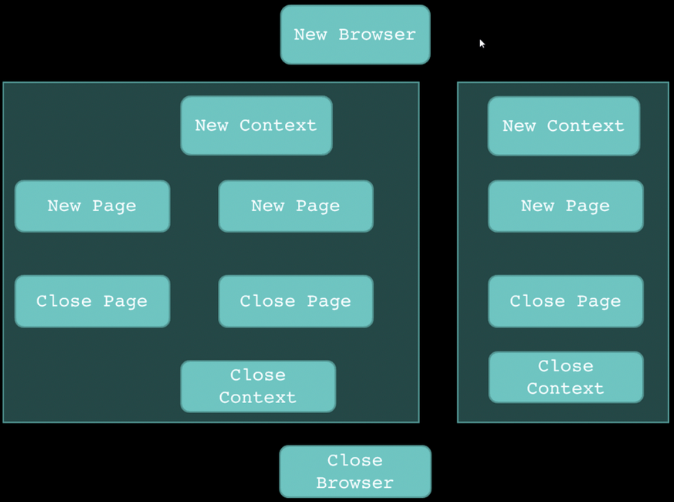
一个完整的playwright流程
就是依次创建browser(浏览器实例)、context(共cookie、session)、page(具体选项卡页面)
然后用页面去模拟操作
完成所有的操作后关闭之前创建的三种对象。
Browser
对应一个浏览器实例(Chromium、Firefox或WebKit),Playwright脚本以启动浏览器实例开始,以关闭浏览器结束。浏览器实例可以在headless或者 headful模式下启动。一个 Browser 可以包含多个 BrowserContext。
BrowserContext
Playwright为每个测试创建一个浏览器上下文,即BrowserContext,浏览器上下文相当于一个全新的浏览器配置文件,提供了完全的测试隔离,并且零开销。创建一个新的浏览器上下文只需要几毫秒,每个上下文都有自己的Cookie、浏览器存储和浏览历史记录。浏览器上下文允许同时打开多个页面并与之交互,每个页面都有自己单独的状态,一个 BrowserContext 可以包含多个 Page。
Page
页面指的是浏览器上下文中的单个选项卡或弹出窗口。在Page中主要完成与页面元素交互,一个 Page 可以包含多个 Frame
Frame
每个页面有一个主框架(page.MainFrame()),也可以有多个子框架,由 iframe 标签创建产生。在playwright中,无需切换iframe,可以直接定位元素(这点要比selenium方便很多)。
打开页面模板(单线程)
from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
###################这里将是操作页面的代码块##################
pass
#############################################################
page.close()
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)异步编程
import asyncio是一种编程模式,用于处理需要耗时操作或可能阻塞线程的任务。
在传统的同步编程中,代码按照顺序执行,每个操作会阻塞当前线程直到完成。
而异步编程则允许程序在执行耗时操作时继续执行其他任务,而不需要等待操作完成。
打开页面模板(异步)
何时使用同步,何时使用异步,简单来说,如果希望用多线程,那么使用异步,单线程使用同步。举个简单例子,比如我想爬取300章小说,如果用单线程去爬,那么时间是线性的,爬取每一章节所使用的时间积累起来就是最终所用的总时间;如果用多线程,比如说同时用10个线程去爬,那么理论上总时间就是单线程所用时间的1/10。
相反,如果我只是想获取某一个页面的内容,那么直接单线程就完事
import asyncio
from playwright.async_api import Playwright, async_playwright, expect
async def run(playwright: Playwright) -> None:
browser = await playwright.chromium.launch(headless=False)
context = await browser.new_context()
page = await context.new_page()
#########################操作页面的代码块#############
pass
####################################################
await page.close()
await context.close()
await browser.close()
async def main() -> None:
async with async_playwright() as playwright:
await run(playwright)
asyncio.run(main())在新的窗口打开链接
with context.expect_page() as new_page_info:
# page为已建立的page对象
page.click('"立即注册"')
# 新的page对象
new_page = new_page_info.value
# 关闭新的窗口page对象
new_page.close() 在当前页面打开新的窗口
with page.expect_popup() as page1_info:
# page为已建立的page对象
page.get_by_role("button", name="高级搜索").click()
# 新的page对象
page1 = page1_info.value
# 关闭新窗口
page1.close() 打开时最大化窗口
# 还要配合context中设置 no_viewport = True
args = ['--start-maximized']
no_viewport=True无头模式
# 显示界面,为True时隐藏界面
headless = False 网络代理
proxy = {
"server": "http://127.0.0.1:8080", # 代理服务器的地址
"bypass": "*.http://bing.com", # 不使用代理的域名
"username": "Mike", # 代理服务器的用户名
"password": "123456" # 代理服务器的密码
}指定下载保存路径
downloads_path = r"d:\"定义打开窗口的具体大小
viewport={ 'width': 1280, 'height': 1024 }忽略https错误
ignore_https_errors=True模拟移动设备
#默认为 False
is_mobile=True支持触摸事件
#默认为 False
has_touch=True绕过内容安全策略
#默认为 False
bypass_csp=True指定浏览器的语言和地区
locale=en-US指定浏览器的地理位置
# latitude(纬度)longitude(经度) accuracy(精度)
geolocation={“latitude”: 31.2304, “longitude”: 121.4737, “accuracy”: 10}跳转链接
page.goto(url)点击元素
page.click(selector)输入文本
page.fill(selector, value)截图
page.screenshot(path)