reCAPTCHA
背景
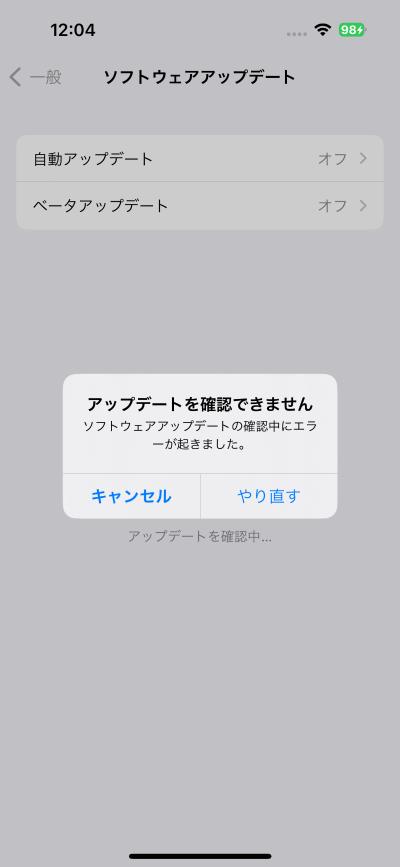
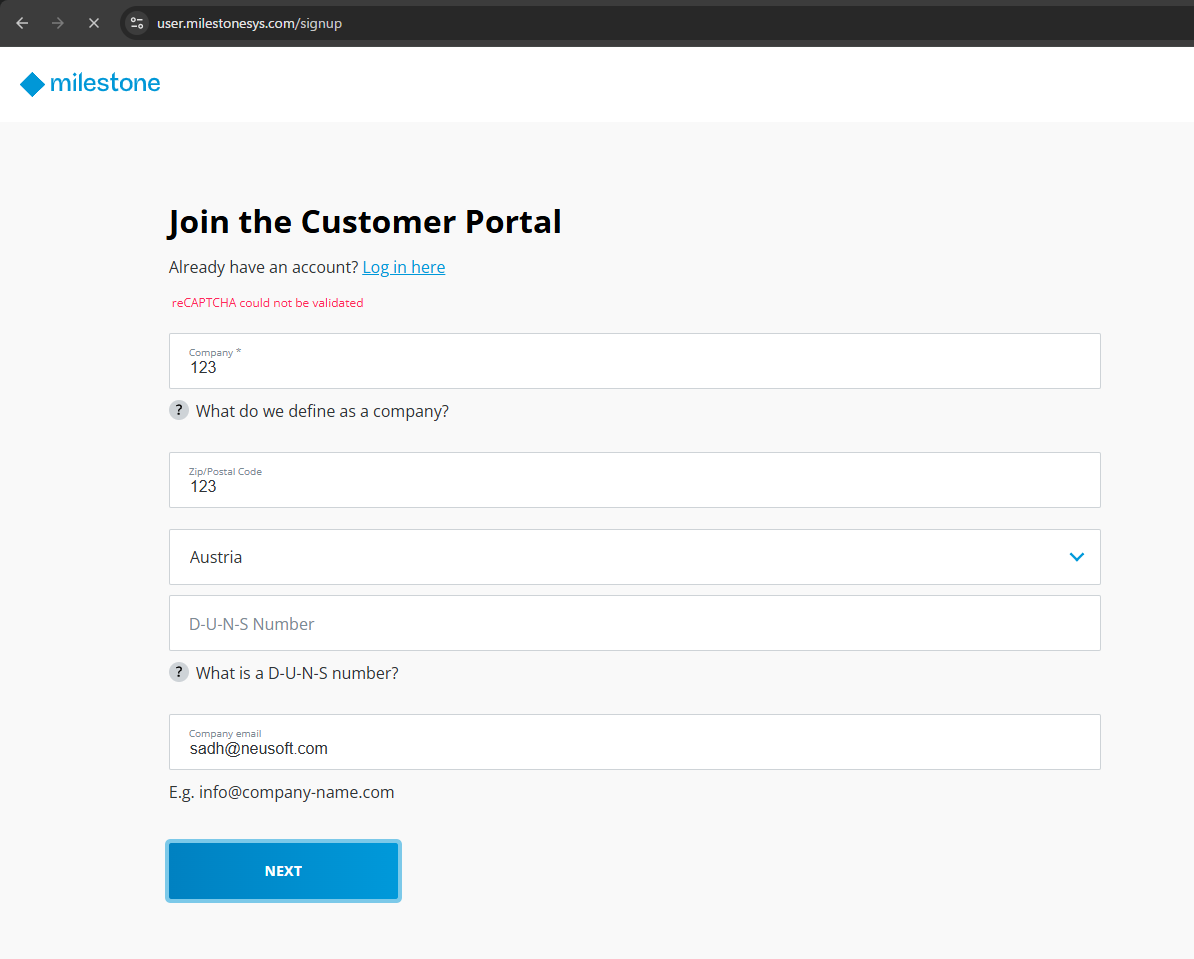
在使用国内大陆的网络进行Milestone的账号注册时,出现了报错【reCAPTCHA could not be validated】
最后使用日本网络成功显示并通过reCAPTCHA验证,记录一下。
CAPTCHA
CAPTCHA (Completely Automated Public Turing Test to tell Computers and Humans Apart)(全自动区分计算机和人类的图灵测试)
是一种用于区分人与计算机自动程序的挑战应答系统测试。
几乎所有正规的论坛都要求注册时输入验证码,这是为了防止乱发垃圾广告的家伙用注册机来恶意注册。
这个源自美国卡内基-梅隆大学的发明被称为CAPTCHA(用于区分人类与电脑的全自动图灵测试),因为注册者需要辨识图片上七歪八扭的文字,而这项工作只有真正的人类才能完成。
reCAPTCHA
简介
reCAPTCHA 是由 Google 提供的一项免费服务,旨在保护网站免受垃圾邮件和自动化攻击(通常是由机器人程序发起的)。其主要目的是确保提交表单的用户是真人,而不是恶意的自动程序。
reCAPTCHA 的工作原理
reCAPTCHA 通过要求用户完成一项任务来判断其是否为人类。这些任务包括:
点击复选框:用户需要点击一个复选框来确认自己是人类。这个过程对于机器人来说非常困难,因为它依赖于视觉识别和用户的微妙反应。
图像选择题:系统会展示一组图片,并要求用户选择特定类别的图片(如“选择所有含有交通灯的图片”)。这种验证方式让系统通过视觉判断来识别用户的身份。
文本验证码:这是最传统的验证方式,系统会展示一组扭曲的字母或数字,要求用户输入正确的内容。
行为分析(Invisible reCAPTCHA):这种方式更加隐形,不需要用户进行任何显式验证,只通过分析用户在网页上的行为(如点击、滑动等)来判断是否为机器人。
为什么需要 reCAPTCHA?
随着网络自动化技术的进步,许多恶意软件、机器人程序开始自动执行网页上的任务,例如注册账号、发布垃圾邮件、破解密码等。reCAPTCHA 就是为了有效阻止这些自动化行为,确保只有真实用户能够访问和操作网站。
为了改善软件的精确性, reCAPTCHA 会将最困难的词发送给多个用户并挑选其中有相同答案的作为正确的答案。据说准确率能够达到99%。用户每使用一次这个程序,实际上就是在帮助数字重现1908年《纽约时报》上的某一页,或者其它古书中的一页,这对考古学具有重大的意义。
因为需要辨识图片上七歪八扭的文字,这项工作只有真正的人类才能完成。
要知道,全世界的网络用户数以亿计,对个人来说,辨认文字所花的几秒时间微不足道,但如果将所有网民的力量利用起来,那便能完成难以想象的浩大工程,而这正是美国宾夕法尼亚州匹兹堡市的CMU研究小组正在做的事。
该小组受一家名为“互联网档案馆”的非营利组织委托,要将海量的古老书籍和手稿通过OCR(光学字符识别)软件转化为电子文本,以方便电脑储存和查询。然而,由于原稿的质量太差,可怜的电脑每扫描十个单词就会错读一个,唯一解决的办法就是人工核对,而这样的工作显然不是一个人或一个小组可以胜任的。
为了提高用户辨识文字的正确率,他们往往被要求辨认两个单词,其中一个的答案已经知晓。这样以来,正确辨认出有答案的那个单词的用户,很有可能也会正确辨认另一个单词。有时候,CMU也会将一个未经辨认的单词提交给不同的用户,如果得到的是相同的答案,那这个答案便可以肯定是正确的。
由于许多人气极高的网站,如Facebook、Twitter和StumbleUpon等,都采用了reCAPTCHA,CMU每天都可以处理大约一百万个单词。不过,按照这个速度,要电子化“互联网档案馆”提供的所有文本,估计还需要400年。
reCAPTCHA 的优势
提高安全性:能够有效减少垃圾邮件、伪造用户和网络攻击。
易于集成:对于开发者而言,reCAPTCHA 提供简单的 API,方便在网站或应用中集成。
用户体验优化:最新版本的 reCAPTCHA(Invisible reCAPTCHA)无需用户额外操作,使得用户体验更加顺畅。
国内没法验证reCAPTCHA的解决方法
使用插件替换使用官方地址的 reCaptcha 为官方镜像地址,让墙内用户的 reCaptch 能正常显示。
使用tampermonkey安装脚本的方法参见我的其他文章
前端开发嵌入reCAPTCHA
reCaptcha是Google公司的验证码服务,方便快捷,改变了传统验证码需要输入n位失真字符的特点。reCaptcha在使用的时候是这样的:
只需要点一下复选框,Google会收集一些鼠标轨迹、网络信息、浏览器信息等等,依靠后端的神经网络判断是机器还是人,绝大多数验证会一键通过,无需像传统验证码一样。个人感觉比Geetest要好一些。
但是reCaptcha使用了google.com的域名,这个域名在国内是被墙的,如果使用可以用Nginx配置反向代理,本文的教程无需自行配置,我们直接使用Google官方的反向代理。
获取代码(这一步需要访问国外网站,以后不再需要):首先要有Google账号,登录账号并进入这里:https://www.google.com/recaptcha/admin
在register a new site表单里填写验证名(随便命名)、域名(你要使用reCaptcha 的域),type选择v2,下面的钩钩打上,然后Register即可注册。
接着打开你刚刚创建的验证,找到Keys,记住你的site-key和select

接着可以在客户端和服务端部署了。
客户端部署代码:
在你要添加reCaptcha的页面添加script标签:
<script src='//recaptcha.net/recaptcha/api.js'></script>接着在你要显示reCaptcha验证框的地方添加div容器:
<div class="g-recaptcha" data-sitekey="【此处添加你的site-key】"></div>这样就完成了客户端的部署。
服务端部署代码:
服务端只需要将客户端点击验证码后传回的g-recaptcha-response值和ip以及secret传给Google的API: https://recaptcha.net/recaptcha/api/siteverify 即可
刷新页面,就可以看到验证码已经创建好了:

是不是很简单?当然有的人不喜欢把一堆属性加在dom上,更希望通过js API来使用,没关系,我们来看看显示加载是怎么玩的。
第一步还是引入js资源文件,与上面一样,这个时候我们创建一个验证码容器,其实就是一个装载验证码组件的盒子,如下:
<div id="robot"></div>标签没硬性要求,但一定要加一个id,在js中我们会使用到这个id,接下来是在js中做初始化工作:
grecaptcha.render('robot', {
'sitekey': '6Lfjdd8UAAAAAKzWxI0k59BW5Tcf1C76XPKir1sr', //公钥
'theme': 'light', //主题颜色,有light与dark两个值可选
'size': 'compact',//尺寸规则,有normal与compact两个值可选
'callback': callback, //验证成功回调
'expired-callback': expiredCallback, //验证过期回调
'error-callback': errorCallback //验证错误回调});
刷新页面,你会发现验证码成功展示出来了。聪明的同学已经发现了,grecaptcha.render()就是验证码组件初始化方法,它接受两个参数,前者为组件容器id,也就是我们在div上添加的robot;第二个参数是一个对象,也就是组件相关配置。
有同学就纳闷了,为啥通过API调用显示加载可以加这么多属性,dom形式自动加载能不能加这些配置?当然能,以sitekey为例,在作为标签属性时你得写作data-sitekey,同理,theme用在标签上时也得加上data-前缀,其它属性配置全部如此。
在解释这些属性前,我先附上一个完整的例子,大家直接复制替换下公钥,这样下面的解释可以同步修改理解:
<-- HTML部分 -->验证是否通过
<-- 记得引用js -->
//js部分var callback = function (args) {
console.log(args)
console.log('验证成功');}; var expiredCallback = function (args) {
console.log(args)
console.log('验证过期');}; var errorCallback = function (args) {
console.log(args)
console.log('验证失败');};
var widgetId; var onloadCallback = function () {
// 得到组件id
widgetId = grecaptcha.render('robot', {
'sitekey': '6LcYMd4UAAAAABb4jumQHY9ftHhZ3R0N2QxtACCp',
'theme': 'light',
'size': 'compact',
'callback': callback,
'expired-callback': expiredCallback,
'error-callback': errorCallback
});};
function getResponseFromRecaptcha() {
var responseToken = grecaptcha.getResponse(widgetId);
if (responseToken.length == 0) {
alert("验证失败");
} else {
alert("验证通过");
}};
配置参数说明 sitekey(data-sitekey):客户端秘钥,也就是我们创建的秘钥,这是必填项。
theme(data-theme):验证码组件主题色,默认light,还有一个dark可选,颜色对比如下:
size(data-size):验证码尺寸规则,默认normal也就是长方形,可选值compact正方形,如下:
callback(data-callback):验证成功回调,比如用户点击了我不是机器人复选框,弹出了图片,用户在选择完图片点击右下角的验证,如果验证成功便会触发此回调,比如上方例子验证成功后输出了验证成功以及一大段乱码字符,这段字符官方称为 response token,后端会使用到这个token,我们在后面具体说。
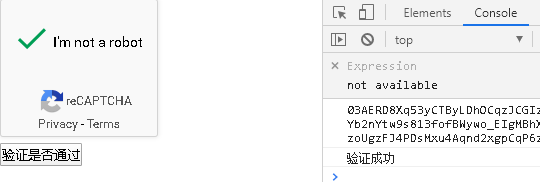
expired-callback(data-expired-callback):过期回调,如果用户第一次验证成功后页面放置一段时间,当前验证就会过期,一旦过期谷歌会自动调用过期回调,如下:
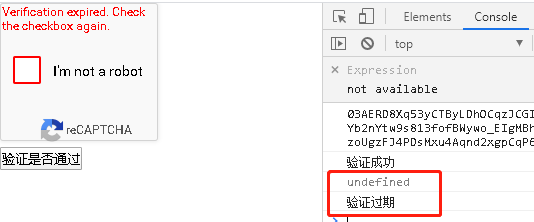
error-callback(data-error-callback):错误回调,验证过程中如果出现错误便会执行这个回调。 API说明 我们已经通过上面的例子了解了初始化组件的API,谷歌验证码一共也就提供了三个API,如下:
grecaptcha.render(container,parameters)grecaptcha.reset(opt_widget_id)grecaptcha.getResponse(opt_widget_id)获取组件验证状态的api,同样接受一个验证码id作为参数,用于获取指定id的验证码验证状态,如果不填,则默认获取第一个验证码状态。获取的结果有两种情况,如果成功,拿到的也就是前面我们说到的response token,如果失败则拿到的是空字符串。
在上文例子我们同样提供了这个方法,大家可以在验证成功和过期两种情况下分别点击验证是否通过的按钮查看不同结果。
有同学一定会纳闷getResponse方法有啥用,说个很简单的例子,用户登录输完了账号密码,只要点击提交按钮,我们就可以通过此方法判断用户有没有提前通过验证,如果通过了再请求登录接口。 - url参数说明 细心的同学一定发现上方例子提供的js 引用后缀有点不同,其实js引用地址也接受三个参数,也不是很复杂,我们来解释下分别表示啥意思:
<script src="https://www.recaptcha.net/recaptcha/api.js onload=onloadCallback&render=explicit&hl=en" async defer 首先,onload,render与hl都不是必填参数,填不填看你自己。
onload:加载所有依赖项后要执行的回调函数的名称,参考上方例子,等资源加载完毕,我们才执行onloadCallback方法初始化组件。
render:是否显式加载组件,默认值为onload,表示自动加载,也就是默认找到第一个class为g-recaptcha的标签来加载组件。例子中我们设置的值为explicit,意思是不启用自动加载,而是根据我们提供的DOM id进行加载。
hl:语言种类,你希望组件用哪种语言展示,详细的语言表参考。如果不设置,则自动检测浏览器语言并作为标准。
OK,到这里,关于复选框模式的使用就全部说完了!!!!!
我们来说说V2隐式验证版本咋玩,由于是不同版本,这里你得重新创建隐式验证版本的秘钥,由于隐式验证版本只是不展示复选框,改为使用按钮点击来触发图片选择验证,其它API,url属性等等都是一样的,这里我就直接给出一个完整的例子:
</p><p><-- html部分 --><br><button class="g-recaptcha" data-sitekey="客户端公钥" data-callback="onSubmit">Submit</button></p><script src="https://www.recaptcha.net/recaptcha/api.js" async defer>
//js部分 function onSubmit(responToken) {
console.log(responToken);
alert('开始提交表单');
};两种复选框模式与隐式验证模式请根据实际业务场景选择使用,不存在谁好谁坏。
集成说明
说完客户端集成,我们来说下服务端如何集成,由于我没学过后端语言,这里就给不出例子了,具体说下怎么用。这里先解释下前后端怎么配合。
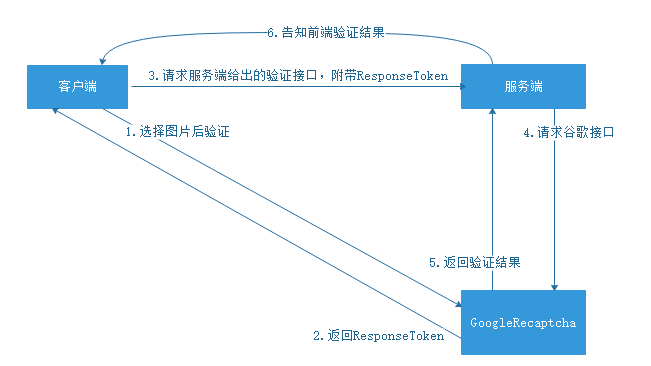
如上图,我们来模拟一次完整的验证过程:
用户点击登录按钮(假设用的是隐式验证模式),弹出了图片选择框,用户选择完正确图片,点击了验证按钮。 这时其实会对谷歌发起请求,请求成功,前端拿到了response token。 前端请求与后端协商好的接口A,把response token带给后端。 后端拿着私钥与response token请求谷歌提供的接口地址B,成功并拿到了验证结果。 后端将这份数据再返回给前端,前端判断成功,这时才开始请求登录接口。 那么后端需要请求的接口地址B就是https://www.google.com/recaptcha/api/siteverify,请求方式为POST。
POST参数有三个,分别是什么:
secret(必填):私钥,也就是我们创建秘钥时,给服务端用的那个秘钥。
response(必填):response token,这个由用户在前端操作后产生,有效期为2分钟,且只能用一次。
remoteip(选填):用户ip。
返回数据格式如下:
{"success": true|false, "challenge_ts": timestamp, // timestamp of the challenge load (ISO format yyyy-MM-dd'T'HH:mm:ssZZ) "hostname": string, // the hostname of the site where the reCAPTCHA was solved "error-codes": [...] // optional }错误码分类这里我就不列了,具体可以查看错误码说明。
用户操作完成前端不是已经知道验证成功失败了吗,何必多次一举还麻烦后端去请求呢。
常理上来说,只通过前端验证也是可以的,只是后端无法感知。
比如博主公司已经有了一套验证码系统,国内用这套,国外用谷歌这套,为了统一验证码验证规则,还是统一由后端提供验证码接口让前端调用,这个就看各位实际业务场景是什么样了。